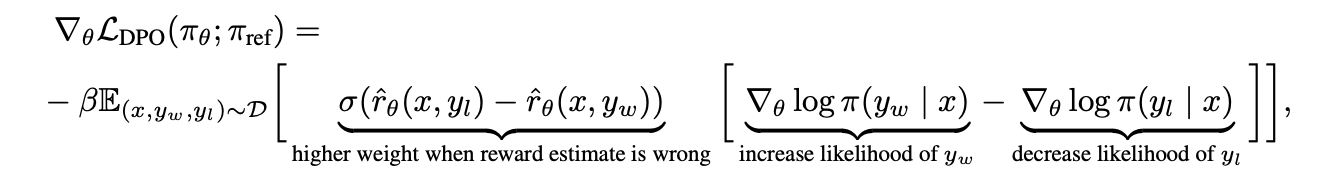Direct Preference Optimization:Your Language Model is Secretly a Reward Model
Rafael Rafailov∗† Archit Sharma∗† Eric Mitchell∗† Stefano Ermon†‡ Christopher D. Manning† Chelsea Finn†
13 Dec 2023
Policy Preferred by Humans
Large-scale unsupervised language models are known to solve various tasks based on extensive knowledges. These generative models produce responses based on their policy. RLHF (Reinforcement Learning from Human Feedback) is the cutting-edge method for generating a policy model that selects desired responses and behavior. However the preference learning stage of RLHF involves significant computational costs due to the nature of Reinforcement Learning. RLHF comprises three steps; (1) Supervised Fine-Tuning for the downstream task(s) of interest. (2) Reward Modeling Phase which models the objective (i.e. reward model). (3) RL Fine-Tuning Phase that involves reinforcement learning because of the discrete nature of language generation, where the objective isn't differentiable.
DPO : RL-Free Algorithm
DPO (Direct Preference Optimization) is an algorithm that is more simple and straightforward than RLHF, however optimizing the same objective. It maximizes the relative log likelihood of preferred responses while having a KL-divergence constraint, which helps the policy maintain stability. The key idea is to simplify the optimization process by leveraging mathematical insights to avoid the complexity of a traditional reward model.
These are the steps involved in DPO to inject (optimize) human preferences into the policy model:
- 1 Pre-train the language model
- 2 Collect preference data

- 3 Reference policy - Fine-tune the pre-trained language model on a supervised dataset to create a strong initial reference policy.
- 4 Direct Preference Optimization - Obtain the probability of human preference data in terms of the optimal policy rather than the reward model. Intuitively, the equation involves (1) the likelihood of preferred completions minus that of dispreferred ones, weighed by (2) how much higher the implicit reward model rates the dispreferred completions, (3) scaled by β (i.e. role in controlling how much the optimized policy can deviate from the reference policy.)