DagoBERT: Generating Derivational Morphology with a Pretrained Language Model
Valentin Hofmann, Janet B. Pierrehumbert, Hinrich schutze
7 Oct 2020
Derivational Morphology rather than Syntax and Semantics
Among all those linguistic knowledges, syntax and semantics came into the lime light in NLP. The paper presents a study about the derivational morphological capability of BERT, suggesting a fully fine-tuned model called DagoBERT. It outperforms the state-of-the-art in derivation generation (DG) task, which is predicting the derivative "unwearable" given an English cloze sentence "this jacket is _" and a base "wear". This research was motivated by the lack of good works on (1) linguistic capalities of pretrained language models while the fact that the subword units which BERT generates are mostly derivational affixes indicates its abundant knowledge about morphology, and (2) derivation generation (DG) task itself.
Linguistics divides morphology into inflection and derivation. From the task of DG's point of view there are two differences between them. First, since derivation covers larger spectrum of meanings, predicting in general with which of them a particular compatible lexeme is impossible. Second, the relationship between form and meaning differs a lot in derivation. These features of derivation make its learning functions from meaning to form much harder.
DagoBERT
The dataset consists of items of (1) the altered (which masked the derivative) sentence, (2) the derivative, and (3) the base since sentential reflect the semantic variability inherent in derivational morphology better than tags. The dataset is created upon 48 productive prefixes, 44 productive suffixes, and 20,259 bases from all publicly available Reddit posts. Additionally, the task is confined in three cases: (1) P (derivatives with one prefix), (2) S (derivatives with one suffix), and (3) PS (derivatives with one prefix and one suffix) because these cases are known to has different linguistic properties.
Task could be re-written as follows:
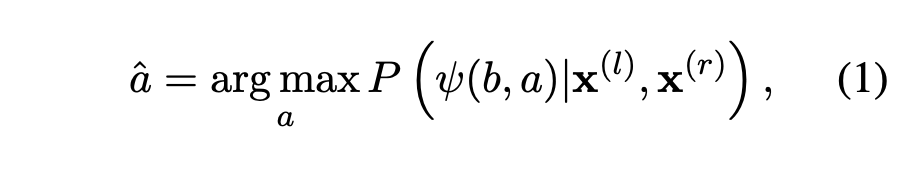
Because of the lack of word-internal formed tokens in BERT's vocabulary, the paper tested four external segmentation methods and among those methods, HYP (Inserting a hyphen between the prefix and the base) was adopted. The paper examined few BERT models and baselines depending on the usage status of finetuning DCL (Derivational Classification Layer), BERT model itself, and both. DagoBERT (Derivationally And Generatively Optimized BERT) is the model which finetunes both the DCL and the model. One of the baseline, which was the former state-of-the-art model on DG task, is LSTM. Provided that POS (Part Of the Speech) is known, LSTM performs better, however, in this case the paper does not consider the setting of POS given.
Overall Performance and Interpretations
DagoBERT basically outperforms BERT, BERT+ (only training DCL on DG) and LSTM for all settings P, S, and PS. Meanwhile the performance gap between DagoBERT and other models is larger in setting P and S because DagoBERT cannot learn statistical dependencies between two masked tokens.
Furthermore, the paper analyzed deeply about the patterns of incorrect predictions. Among these predictions, they found two interesting aspects. First of all, the suffices were clustered in groups with common POS. This indicates that eventhough the DagoBERT predicts the wrong affix, it tends to predict an affix semantically and syntactically congruent to the ground truth. Second, DagoBERT confuses on the same scale, but antonyms. This is related to the recent paper which BERT has difficulties with negated expressions.
Lastly, the paper discussed about the impact of input segmentation. They empirically found out that morphologically correct segmentation, HYP, consistently outperforms WordPiece tokenization. Thus, this indicates that (1) the segmentation impacts how much derivational knowledge can be learned, and (2) the morphologically invalid segmentation cause BERT to force semantically unrelated words to have similar representations.
Where Does Linguistics Meet Computer Science?
Recently, those who studies Linguistics started to compete computer science students in NLP. At first they managed only data, but since the Linguistic knowledge became more crucial in NLP, now they are modifying models such as BERT in order to get higher performance. This phenomenon seems pretty positive because the actual knowledge they have is making task-specific models achieve state-of-the-art.
'BERT' 카테고리의 다른 글
| XLNet = BERT + AR, in Permutation Setting (0) | 2024.05.05 |
|---|---|
| Predicting Spans Rather Than Tokens On BERT (0) | 2023.04.29 |
| Representation Learning Basic (BERT) (0) | 2023.04.25 |
| Robustly Optimized BERT Approach (0) | 2023.01.26 |



