SpanBERT: Improving Pre-training by Representing and Predicting Spans
Allen School of Computer Science & Engineering, University of Washington, Seattle, WA, etc.
18 Jan 2020
SpanBERT
Coreference task is the task of finding all expressions that refer to the same entity in a text. For example, given a text as follows:
"I voted for Nadar because he was most aligned with my values", she said.
'I', 'my', 'she' refer to the same entity, and so do 'Nadar', 'he'. The paper presents a pre-trained model SpanBERT to gain better performance on these span selection tasks based on the reasoning about relationships between two or more spans of text. To talk about the results in advance, SpanBERT achieved the state of the art on the OntoNotes coreference task, and additionally outperformed previous BERT on other downstream tasks including not span-involved tasks. This work demonstrates a remarkable impact of designing high quality training tasks and objectives, rather than adding more data and increasing model size.
This self-supervised pre-training method consists of three major steps that differentiate it from the conventional one:
- First of all, SpanBERT masks tokens randomly in span unit.
Masking tokens in span unit is called a span masking. Basically, the method is to mask on tokens with a span length which is derived from geometric distribution(i.e. span length = Geo(p), which is skewed towards shorter spans). And then it uniformly selects the starting point of the mask.
- Secondly, the paper introduces a novel auxiliary objective called span boundary objectives(SBO).
Span boundary objectives is a method predicting each token of masked span using only the representations of the observed tokens at the boundaries. The paper defines a function, actually an architecture, which its inputs are the external boundary tokens as well as the positional embedding of the target token. Surprisingly, SpanBERT sums the loss from both the masked language model and this function(a 2-layer feed-forward network) for each token x\i while training.
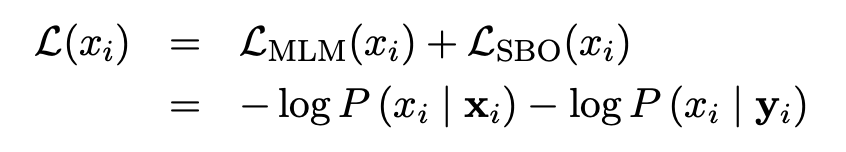
- Lastly, it does not use NSP(Next Sentence Prediction) in order to sample a single contiguous segment of text.
The paper suggests that bi-sequence training(such as NSP) harms the performance of the model because (a) the model benefits from longer full-length context, which single-sentence training provides, and (b) often unrelated context from another document add noise to the masked language model.
Analysis and some Ablation Studies
SpanBERT was assessed on a comprehensive suite of tasks, including Question & Answering, Coreference Resolution, some tasks in the GLUE benchmark, and Relation Extraction. The baselines were BERT and some enhanced variations of BERT. I won't go deep on the baselines, you can just treat the baseline as the original BERT. The overall assessment was that SpanBERT outperforms BERT on almost every task, especially at extractive question answering.
Additionally, the paper went through some interesting ablation studies. First of all, the paper compared the its random masking scheme with linguistically informed masking schemes. The control group involved masking Subword Tokens, Named Entities, Noun Phrases, etc. This study found out that the random Geometric Spans which SpanBERT uses were mostly preferable and at least competitive to other strategies. Secondly, the paper demonstrates that SBO has a huge advantage over NSP. From the ablation study they found out that single-sentence training(i.e. removing NSP) typically improved performance, which I didn't go deep enough, and adding SBO further improved the performance.
Reference
'BERT' 카테고리의 다른 글
| XLNet = BERT + AR, in Permutation Setting (0) | 2024.05.05 |
|---|---|
| Representation Learning Basic (BERT) (0) | 2023.04.25 |
| Morphological Capability of BERT (0) | 2023.04.16 |
| Robustly Optimized BERT Approach (0) | 2023.01.26 |



