
(A quick note) Cheers! Here's to myself who recently got accepted by Carnegie Mellon University; School of Computer Science, Master of Science in Intelligent Information Systems for Fall 2024.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Yang et al.
2 Jan 2020
Representation Learning for NLP
Unsupervised representation learning is known for handling large-scale unlabeled text corpora, which leads to state-of-the-art performance in several downstream natural language processing tasks such as question answering and sentiment analysis. Among these, there are two notable pretraining methods: AR (Autoregressive) language modeling and denoising AE (Autoencoding) based pretraining.
AR language modeling performs density estimation, which estimates the probability distribution of a text corpus. In contrast, AE-based pretraining, such as BERT, aims to reconstruct the original data from corrupted data. BERT achieves better performance than AR models by adapting bidirectional contexts; however, it still has some flaws, such as the independent assumption regarding the pretrain-finetune discrepancy and the usage of an artificial symbol [MASK], which introduces input noise.
XLNet
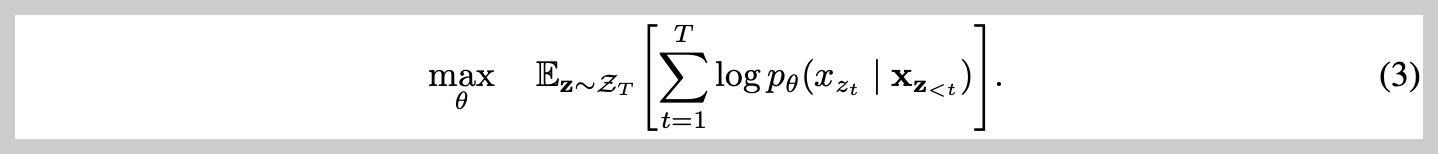
The paper presents XLNet, which retains both the advantages from AR models and BERT. Equation (3) explains the main objective of XLNet. The inner equation maximizes the likelihood in an autoregressive manner with shared parameter Theta, while the Expectation along "z" indicates that it decomposes the likelihood according to the factorization order. (Note that the objective permutes the factorization order, not the sequence order, to avoid the pretrain-finetune discrepancy.)
As for the architecture of XLNet, the paper suggests a modified form of the standard Transformer parameterization. XLNet utilizes Two-Stream Self-Attention, where the content representation of the hidden representation encodes both the context and the contextual information (i.e., position), while the query representation only has access to the contextual information, not the actual content. Additionally, XLNet incorporates ideas from Transformer-XL, after which XLNet is named, enabling it to learn to utilize the memory over all factorization orders.
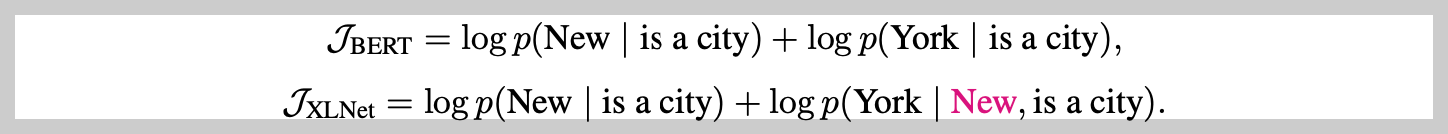
BERT and XLNet both basically perform partial prediction, which means that the models make predictions about a subset of chosen tokens within an input sequence. To better understand the difference between BERT and XLNet, the paper presents a concrete example. We can notice that XLNet is able to capture the dependency between the pair (New, York), while BERT couldn't, because of its independent assumption.
Comparison with BERT

Trained on identical data with similar training recipes, XLNet outperforms BERT on all datasets.
'BERT' 카테고리의 다른 글
| Predicting Spans Rather Than Tokens On BERT (0) | 2023.04.29 |
|---|---|
| Representation Learning Basic (BERT) (0) | 2023.04.25 |
| Morphological Capability of BERT (0) | 2023.04.16 |
| Robustly Optimized BERT Approach (0) | 2023.01.26 |



